
Techniques of NN training. Keep updating.
BERTology: An Introduction!
This is an introduction of recent BERT families.
Efficient Softmax Explained
Softmax encounters large computing cost when the output vocabulary size is very large. Some feasible approaches will be explained under the circumstance of skip-gram pretraining task.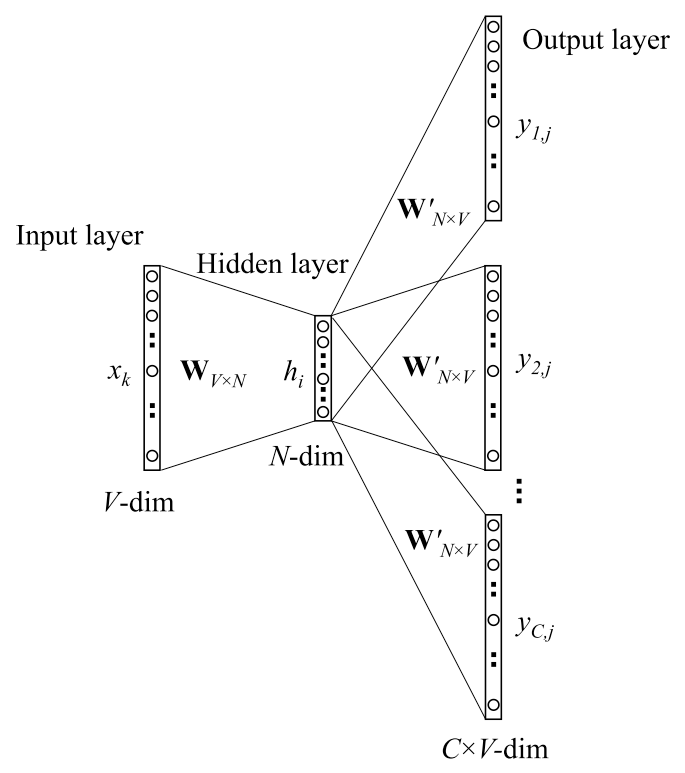
Relational Reasoning Networks
Reasoning the relations between objects and their properties is a hallmark of intelligence. Here are some notes about the relational reasoning neural networks.

Transformer Variants: A Peek
This is an introduction of variant Transformers.[1]
FLOPs Computation
FLOPs is a measure of model complexity in deep learning.
Counting the Number of Parameters in Deep Learning
A guide to calculate the number of trainable parameters by hand.
Dynamic Programming in NLP
Dynamic Programming (DP) is ubiquitous in NLP, such as Minimum Edit Distance, Viterbi Decoding, forward/backward algorithm, CKY algorithm, etc.
LeetCode: partition equal subset sum
Implementation Practical Misc
Some implementation magic.