
A capsule is defined as a group of neuron instantiations whose parameters represent specific properties of a specific type of entity. Here is a brief note of Capsule networks[1][2].
Decoding in Text Generation
Summary of common decoding strategies in language generation.
Sparse Matrix in Data Processing
It is wasteful to store zeros elements in a sparse matrix, especially for incrementally data. When constructing tf-idf and bag-of-words features or saving graph ajacent matrix, non-efficient sparse matrix storage might lead to the memory error. To circumvent this problems, efficient sparse matrix storage is a choice.
Clustering Methods: A Note
Notes of clustering approaches.
An Introduction to Graph Neural Networks
Graph Neural Networks (GNNs) has demonstrated efficacy on non-Euclidean data, such as social media, bioinformatics, etc.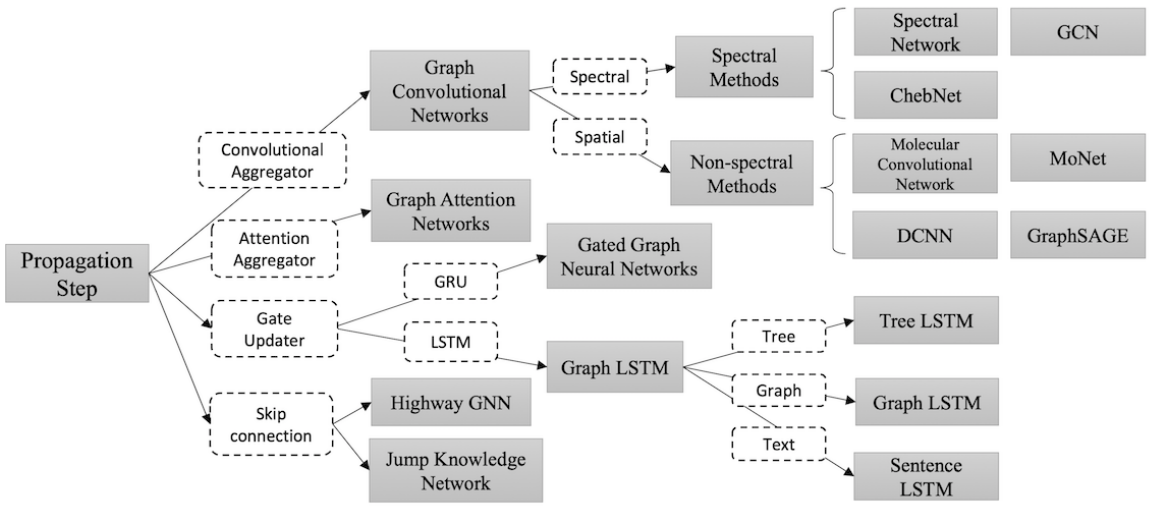
Generative Adversarial Networks
GANs are widely applied to estimate generative models without any explicit density function, which instead take the game-theoretic approach: learn to generate from training distribution via 2-player games.
Variational Autoencoders
This is a concise introduction of Variational Autoencoder (VAE).
An Introduction to Bloom Filter
When we check and filter out the duplicates for a web crawler, bloom filter is a good choice to curtail the memory cost. Here is a brief introduction.
Likelihood-based Generative Models II: Flow Models
Flow models are used to learn continuous data.
Likelihood-based Generative Models I: Autoregressive Models
The brain has about 1014 synapses and we only live for about 109 seconds. So we have a lot more parameters than data. This motivates the idea that we must do a lot of unsupervised learning since the perceptual input (including proprioception) is the only place we can get 105 dimensions of constraint per second.
(Geoffrey Hinton)