
Text classification is one of the most important fundamental NLP tasks. Its goal is to assign labels to texts, including sentiment analysis, spam detection, topic labeling, Twitter hashtag prediction, domain detection, etc.
Embedding Pretrained Linguistic Prior in a Nutshell
Pretraining on ImageNet followed by domain-specific fine-tuning has illustrated compelling improvements in computer vision research. Similarly, Natual Language Processing (NLP) tasks could borrow ideas from this.
Employing pretrained word representations or even langugage models to introduce linguistic prior knowledge has been common sense in amounts of NLP tasks with deep learning.
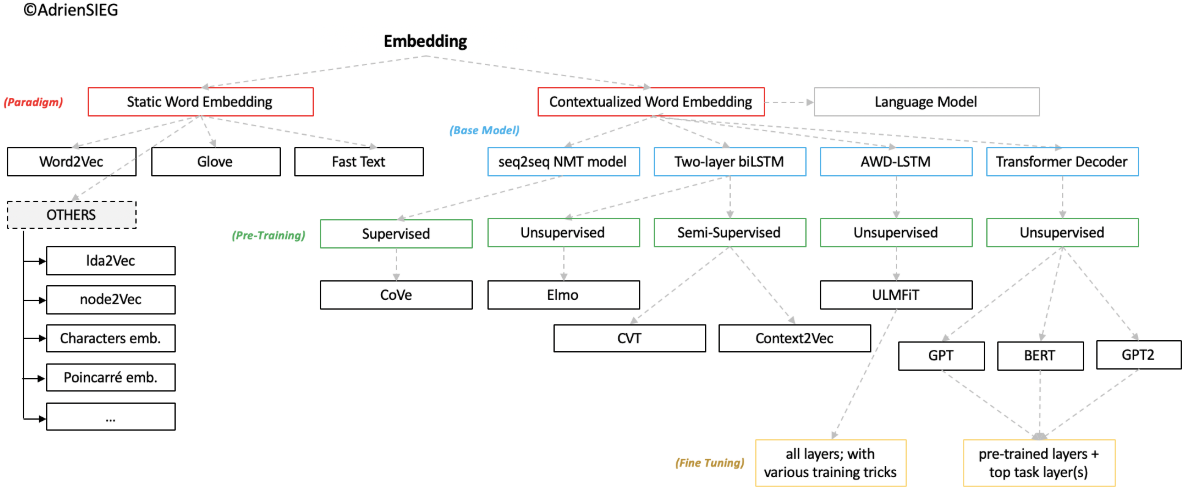
Industrial Tricks for Named Entity Recognition
Why is NER hard in the industry?
This blog dicusses several frequently occurred problems and possible solutions.

Active Learning Overview
Active learning (called query learning or optimal experimental design in statistics). The key hypothesis is, if the learning algorithm is allowed to choose the data from what it learns, it will perform better with less training.
Named Entity Recognition Overview
Name Entity Recognition (NER) labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names.
Data Augmentation for Deep Learning Models
Neural nets require large scale dataset during training process. However, it is quite expensive to have the access to enough data size. One approach to deal with this issue is Data augmentation, which means increasing the number of data points.
Evaluation Metrics of Named Entity Recognition
Here we briefly introduce some common evaluation metrics in NER tasks, considering both extracted boundary and entities.
NLP Basics
A note for NLP Interview.